





让应用程序在运行时适应客户需求最常用的方法之一就是使用脚本。但是事物总有两面性,无一例外。脚本这种方法并非只有好的一面,我们需要在灵活性和可管理性之间权衡。本文不是在理论上讨论优缺点的文章,而是从实际出发,展示使用脚本的几种不同方式,并介绍了一个Spring库,这个库提供了方便的脚本基础设施和一些其他的有用功能。
介绍
脚本(也称为插件架构)是使应用程序在运行时可自定义的最直接的方法。很多时候,脚本并不是设计到应用程序中的,只是偶尔会用到。比如说,在功能描述中有一部分描述地非常模糊,我们不能再耗费额外一天时间去分析这个描述模糊的业务。这时我们决定创建一个扩展点并调用一个脚本存根,然后在晚些时候再详细定义这个脚本的业务逻辑。
使用这种方法有很多众所周知的优点和缺点:例如可以非常灵活地在运行时定义业务逻辑并且可以在重新部署方面节省大量时间,但是使用脚本也会导致不能对系统进行全面地测试,因此,会给系统在安全性、性能等方面带来不可预测的问题。
后续对使用脚本的方式的讨论可能对已经决定在Java应用程序中坚持使用脚本插件的用户或正在考虑将其添加到代码中的用户都会有所帮助。
直接编写脚本
使用Java JSR-233 API在Java中执行脚本是很简单的任务。有许多实现了此API的产品级脚本执行引擎,比如Nashorn、JRuby、Jython等。因此在java添加一些脚本的魔法很容易实现,如下所示:
Map parameters = createParametersMap();
ScriptEngineManager manager = new ScriptEngineManager();
ScriptEngine scriptEngine = manager.getEngineByName("groovy");
Object result = scriptEngine.eval(script.getScriptAsString("discount.groovy"),
new SimpleBindings(parameters));
显然,如果你的代码库中的脚本文件很多,那么将这些调用代码分散在整个应用程序并不好。因此,你可能会将此代码段提取到一个工具类的单独方法中。也可能会考虑地更远一些:创建一个专用的类(或一组类),根据业务领域对脚本化业务逻辑进行分组,比如:PricingScriptService类。这样我们就可以将对evaluateGroovy() 方法的调用封装到一个强类型的方法中,但这里仍然存在一些重复的代码:所有方法都包含构建参数Map、加载脚本文本以及调用脚本引擎的代码,类似于:
public BigDecimal applyCustomerDiscount(Customer customer, BigDecimal orderAmount) {
Map params = new HashMap<>();
params.put("cust", customer);
params.put("amount", orderAmount);
return (BigDecimal)scripting.evalGroovy(getScriptSrc("discount.groovy"), params);
}
这种方法在了解参数类型和返回值类型方面有更大的透明度。但是别忘了,需要在编码标准文档中添加一条:禁止调用“解包”了的脚本引擎!
CUBA平台中增强版的脚本引擎
尽管使用脚本引擎非常简单,但如果代码库中有很多脚本,就可能会遇到一些性能问题。比如,在报表中使用groovy模板,并且同时运行大量报表。那么,你迟早会发现“简单”脚本成为性能瓶颈。
这就是为什么有些框架在现有API上构建自己的脚本引擎 :添加一些功能来改善性能、监控脚本的执行、支持多种脚本语言,等等。
例如,在CUBA框架中,有一个相当复杂的Scripting引擎,提供一些用于改善脚本实现和执行的功能,例如:
- 对类进行缓存, 避免脚本的重复编译。
- 使开发人员能够使用Groovy和Java语言编写脚本。
- 提供用于脚本引擎管理的JMX bean。
所有这些都改善了性能和可用性,但这些还只是用于创建参数Map、获取脚本文本等低级API,因此我们仍然需要将这些脚本分组到高阶模块,以便在应用程序中更高效地使用脚本。
在这里,有必要提一下GraalVM引擎,这是一个由Oracle开源实验性产品。GraalVM引擎及其多语言API允许开发人员使用其他语言扩展Java应用程序。所以,我们也许能看到Nashorn退役之时,我们也可以在同一个源文件中使用不同的编程语言。但是,这些还需要等待。
Spring 框架对脚本的支持
Spring框架在JDK API之上内置了对脚本的支持,可以在org.springframework.scripting.* 包中找到很多有用的类。有执行器(evaluators)、工厂(factories)等所有用于构建脚本支持所需的工具。
除了低级别API之外,Spring 框架还有一个可以在应用程序中简化脚本处理的实现 - 可以使用动态语言定义Bean,文档链接。
需要做的就是使用像Groovy这样的动态语言实现一个类,并在配置XML中描述一个bean,如下所示:
<lang:groovy id="messenger" script-source="classpath:Messenger.groovy">
<lang:property name="message" value="I Can Do The Frug" />
</lang:groovy>
之后,就可以使用XML配置将Messenger bean注入到应用程序的类中。由于AOP的帮助,在Bean对应的脚本文件发生变化时,这个Bean可以自动“刷新”。
这种方法看起来不错,但是作为开发人员,如果想充分发挥动态语言的威力,应该为bean实现完整的类。在现实中,脚本可能是纯函数,因此需要在脚本中添加一些额外的代码使其与Spring兼容。此外,现在一些开发人员认为XML配置与注解相比,已经“过时”,并且尽量避免使用它,因为会觉得bean的定义和注入分散在Java代码和XML代码中。虽然这更像是审美问题而不是性能/兼容性/可读性等问题,但我们也许会把它考虑在内。
脚本:挑战和想法
任何事情都有代价,当为应用程序添加脚本支持功能时,可能会遇到一些挑战:
可管理性 - 通常脚本分散在应用程序中,因此管理大量的evaluateGroovy(或类似的)调用会很困难。
可发现性 - 如果在调用的脚本中出现问题,很难在源代码中找到实际的出错点。但是在IDE中能很轻松地找到所有脚本调用点。
透明度 - 编写脚本扩展并非是一件简单的事情,因为没有关于要传递给脚本的变量的信息,也没有关于脚本返回的结果的信息。最终,脚本只能由开发人员通过查看源代码完成。
更新 - 部署(更新)新脚本总是存在危险性,在用于生产环境之后很难进行回滚。
将对脚本方法的调用隐藏在常规Java方法下似乎可以解决大部分这种问题。更好的方法是注入“脚本化”bean并使用有意义的名称调用其方法,而不是从通用类中调用另一个“eval”方法。这样,我们的代码将可以自描述,开发人员不需要查看文件“disc_10_cl.groovy”来确定参数名称、类型等。
另一个优点 - 如果所有脚本都有与之关联的唯一java方法,则可以使用IDE中的“Find Usages(查找用例)”功能轻松找到应用程序中的所有扩展点,同时也可以知道此脚本的参数和返回值是什么。
这种编写脚本的方式也使得测试变得更简单 - 我们不仅可以“像往常一样”测试这些类,而且如果需要也可以使用Mocking框架。
所有这些都再次提及本文开头提到的方法 - 用于脚本化方法的“特殊”类。如果我们更进一步对开发人员隐藏对脚本引擎的调用、参数创建等操作用会怎么样?
脚本仓库概念
这个想法很简单,所有使用过Spring框架的开发人员都应该很熟悉。我们只是创建一个java接口,并以某种方式将其方法链接到脚本。举例来说,Spring Data JPA使用的就是类似的方法,其中接口方法基于其名称转换为SQL查询,然后由ORM引擎执行。
实现这个概念可能需要什么?
可能需要一个类级别的注解来帮助我们检测脚本仓库接口并为它们构造一个特殊的Spring bean。
还有一个方法级别的注解,可以帮助我们将方法链接到具体的脚本实现。
如果给接口方法提供一个默认实现,这个实现不是简单的存根,而是一部分有效的业务逻辑,这样会更好。这样的话,在业务分析人员实现算法之前可以一直使用这个默认实现。或者我们可以让他/她(业务专家)自己来编写这个脚本 :-)。
假设需要创建根据用户的个人资料计算折扣的服务。业务分析师表示,我们可以安全地假设默认情况下可以为所有注册客户提供10%的折扣。对于这种情况,我们可能会考虑以下概念代码:
@ScriptRepository
public interface PricingRepository {
@ScriptMethod
default BigDecimal applyCustomerDiscount(Customer customer,
BigDecimal orderAmount) {
return orderAmount.multiply(new BigDecimal("0.9"));
}
}
当有了合适的折扣算法实现时,groovy脚本可以这样写:
-------- file discount.groovy --------
def age = 50
if ((Calendar.YEAR - cust.birthday.year) >= age) {
return amount.multiply(0.75)
}
--------
这一切的最终目标是让开发人员只实现一个接口和折扣算法脚本,并且不需要笨拙地调用那些 “getEngine” 和 “eval”方法。脚本解决方案应处理所有的逻辑:当方法被调用时拦截调用,查找并加载脚本文本,执行它并返回结果(如果没找到脚本文本,则执行默认方法)。理想的用法大概如下:
@Service
public class CustomerServiceBean implements CustomerService {
@Inject
private PricingRepository pricingRepository;
//Other injected beans here
@Override
public BigDecimal applyCustomerDiscount(Customer cust, BigDecimal orderAmnt) {
if (customer.isRegistered()) {
return pricingRepository.applyCustomerDiscount(cust, orderAmnt);
} else {
return orderAmnt;
}
//Other service methods here
}
我想这种脚本调用具有可读性,并且这种调用方式对java开发人员来说不会陌生。
这些是想法,并且用这些想法来基于 Spring Framework 创建脚本仓库的实现库。这个库包含从不同来源加载并执行脚本的基础设施,同时也提供了一些API, 开发人员可以使用这些API对这个库进行扩展。
它如何工作
这个库创建了一些注解(以及XML配置,有的开发人员可能偏好于使用XML配置),在上下文初始化期间,为使用@ScriptRepository注解的所有Repository接口初始化动态代理。这些代理发布为实现Repository接口的单例bean,这意味着可以使用@Autowired或@Inject将这些代理注入到bean中,如上一节中的代码片段所示。
在其中一个应用程序的配置类上使用@EnableScriptRepositories注解来激活脚本Repositories。这种方法类似于开发人员熟知的其它Spring 注解(如 @EnableJpaRepositories 或 @EnableMongoRepositories)。对于此注解,需要指定应与 JPA repository相似的扫描包名数组。
@Configuration
@EnableScriptRepositories(basePackages = {"com.example", "com.sample"})
public class CoreConfig {
//More configuration here.
}
如前面所示,我们需要使用 @ScriptMethod 注解来标记脚本Repository中的每个方法(库也提供 @GroovyScript 和 @JavaScript),为方法调用添加元数据并注明这些方法是脚本方法。当然,也支持脚本方法的默认实现。这个解决方案的所有组件都显示在下图中。蓝色图形与应用程序代码相关,白色图形与库相关。Spring bean 有 Spring Logo 。
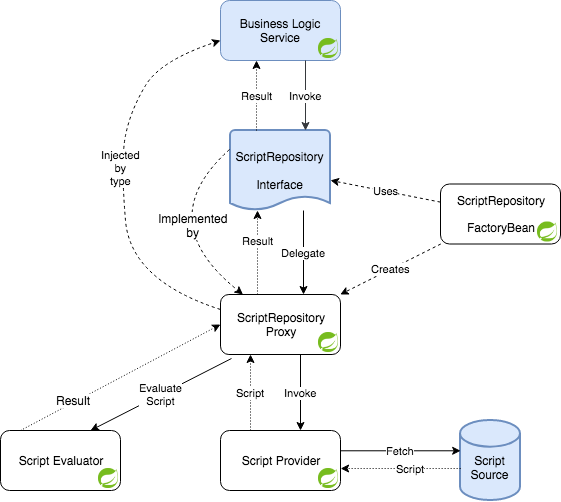
当调用接口的脚本方法时,它会被代理类拦截,代理类会查找两个 bean - 一个是用于获取实现脚本内容的provider,另一个是用于获取执行结果的evaluator。在脚本执行之后,结果将返回给脚本的调用方。可以用 @ScriptMethod 注解属性指定provider和evaluator以及执行超时(这个库也为这些属性提供了默认值):
@ScriptRepository
public interface PricingRepository {
@ScriptMethod (providerBeanName = "resourceProvider",
evaluatorBeanName = "groovyEvaluator",
timeout = 100)
default BigDecimal applyCustomerDiscount(
@ScriptParam("cust") Customer customer,
@ScriptParam("amount") BigDecimal orderAmount) {
return orderAmount.multiply(new BigDecimal("0.9"));
}
}
你可能会注意到 @ScriptParam 注解 - 我们使用它们为方法的参数提供名称,这些名称应该用在脚本中,因为 Java 编译器会在编译时删除实际的参数名称。也可以不用这个注解,此时,需要以 “arg0”、“arg1” 等来命名脚本参数,只是这会影响代码的可读性。
默认情况下,这个库提供可以从文件系统读取 groovy 和 javascript 文件的provider以及用于两种脚本语言的基于JSR-233 的 evaluator。可以为不同的脚本存储和执行引擎创建自定义的provider和evaluator。所有这些设施都基于 Spring 框架接口(org.springframework.scripting.ScriptSource 和 org.springframework.scripting.ScriptEvaluator),因此可以复用所有基于 Spring 的类。例如,使用StandardScriptEvaluator代替默认的类。
Provider(以及evaluator)会作为 Spring bean 发布,为了提高灵活性,脚本repository代理会按名称解析 - 可以在不更改应用程序代码的情况下将默认执行程序替换为另外一个,只是在应用程序上下文中替换一个 bean。
测试和版本控制
由于脚本很容易更改,因此我们需要确保在改变脚本时不会破坏生产服务器。这个库与 JUnit 测试框架兼容,这里没有特殊之处。由于在基于 Spring 的应用程序中使用这个库,因此在将脚本更新到生产环境之前,可以使用单元测试和集成测试将脚本作为应用程序的一部分来测试,测试中也支持模拟(mocking)框架。
此外,可以创建一个脚本provider,从数据库甚至从 Git 或其它源代码控制系统读取不同版本的脚本文本。在这种情况下,如果生产环境中出现问题,可以很容易切换到新版本的脚本或回滚到之前版本的脚本。
结论
这个库有助于在代码中使用脚本,提供以下功能:
通过引入 java 接口,开发人员可以获取到脚本参数及其类型信息。
Provider和evaluator可以避免分散在饮用程序各处的脚本引擎调用。
我们可以使用 “Find usages (references)” IDE 命令或只通过方法名称进行简单的文本搜索就能轻松找到应用程序代码中的所有脚本使用的地方。
另外,这个库也支持Spring Boot自动配置,并且还可以使用熟悉的单元测试和模拟(mocking )技术在脚本部署到生产环境之前对其进行测试。
这个库有一个用于在运行时获取脚本元数据(方法名称、参数等)的 API,也可以获取封装后的执行结果,如果不想编写 try..catch 块来处理脚本抛出的异常的话,另外,如果更习惯用XML格式来存储配置的话,这个库也支持。
此外,可以使用注解的超时时限参数对脚本执行时间进行限制。
这个库的源码:https://github.com/cuba-rnd/spring-script-repositories