





简介
多租户是一种软件服务运营模式,在这种模式下,多个或一个应用程序的多个实例在一个共享的环境中运行,实例(租户)之间在逻辑隔离,在物理上是一体的。
公寓是多租户架构的完美案例。这种模式下对安全(大门)、电、水和其他设施进行集中管理。这些设施归公寓所有者所有,由租户共享。
这篇文章中,我们将介绍多租户架构,并探讨 CUBA 对多租户架构的一种实现。
多租户简史
我们从另外一个话题开始 - 软件分发和部署。最初,软件通过物理介质(磁带、光盘、闪存驱动器)进行分发。通常,您必须将软件部署到本地网络的服务器上,那时的网络通道没有现在这么发达。
互联网发展很快,现在我们拥有以百兆、千兆计的带宽。这时,通过互联网交付软件变得更加容易 - 下载 100 兆字节所需的时间比去商店购买该软件的 DVD 或蓝光光盘花的时间更少。
同时,网络和计算硬件的发展促进了一个新市场的涌现 - 虚拟化,然后出现了 IaaS(基础设施即服务),这时给服务器安装软件产品并且授权用户访问也变地很容易。
最终,供应商采用了 SaaS - “软件即服务” 分发模型。对于用户来说,只需要购买已部署好的软件产品的访问权限,而无需维护本地服务器,因此总拥有成本较低。
为每个客户都安装一次软件实例仍然不是一件简单的事,因此软件开发人员开始使用多租户架构来简化部署和维护。您可以在互联网上看到很多 SaaS 部署。例如,Salesforce,在很久以前就开始采用多租户架构和 SaaS 分发。
但是实现多租户应用程序是一项艰巨的任务。您必须考虑如何隔离客户数据、协调资源消耗、公共数据共享等。应对这些挑战的最新方案是 PaaS(platform-as-a-service)模型。
容器化和 DevOps 开发流程是多租户应用程序的主要挑战者。如今,借助 Docker 和 Kubernetes 之类的产品,启动一个新的“服务器”甚至整个“基础架构”非常容易,包括数据库、应用程序服务、缓存服务器和反向代理。对于开发人员而言,实施单租户应用程序然后为每个新客户部署该应用程序的新实例要简单得多,实际上,该过程只需几秒钟,甚至是完全自动化的。有时,它可能会导致另一种现象,称为 “cube sprawl”,但这个世界上没有 “银弹”。
尽管如此,现在实现多租户应用程序仍是件重要的事情(参考 Salesforce、Work Day、Sumo Logic 等),仍然需要开发此类产品。让我们回顾一些实现多租户的方法,然后看看 CUBA 平台可以在此领域提供什么。
多租户的实现
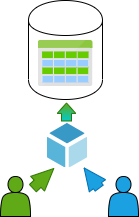
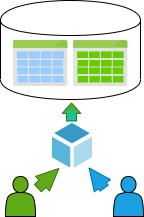
多租户的优点及缺点
多租户架构的优点和缺点:
优点:
- 成本低 - 与其他解决方案相比,它通常更便宜。
- 维护简单 - 管理员只需要维护一个系统。
- 易于扩展 - 添加新租户是一个标准化,快速且简单的过程。
缺点:
- 开发复杂 - 与单租户相比,创建多租户应用程序是一项更为复杂的任务。
- 灵活性受限 - 特别是对于面向多个国家的应用程序而言。个人数据保护、业务逻辑计算等可能有不同的要求。
- “吵闹的邻居(Nosy neighbor)” 问题。另一个租户可能会访问到您的数据或消耗您的资源。
- 还有 “单点故障” 问题。如果所有客户共享同一资源(例如数据库),则在此资源不可用时,所有客户都会受到影响。
CUBA 中的多租户支持
CUBA 框架允许我们动态修改数据库查询,行级安全控制就是使用的这个机制。扩展该机制以支持多租户应用程序非常容易。
使用 CUBA 实施多租户应用程序时,需要确定哪些实体将存储特定于租户的数据。例如,以 宠物诊所示例应用程序 为例。下图表示了该应用程序的数据模型。
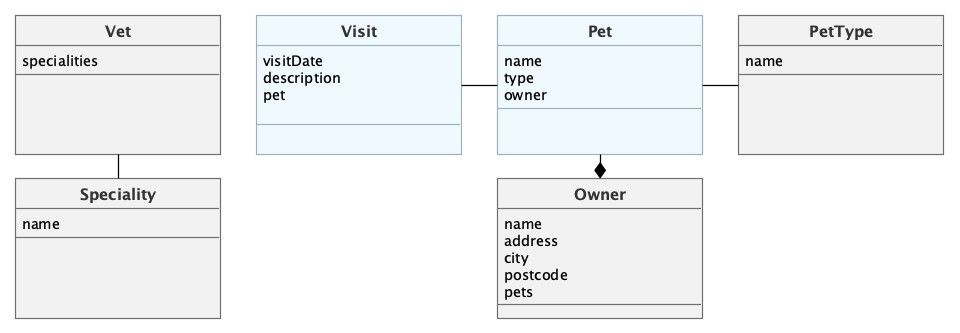
您可以使所有实体都特定于租户,但是还有另一种选项 - 共享某些字典实体。可以认为不同客户之间共享兽医专业(veterinarian specialties)和宠物类型(pet types)是“安全的”。对于其他一些“通用”数据,也是可以共享的。这样可以节省一些空间,并确保所有租户的 “标准” 数据保持一致,这样在实现业务逻辑时我们可以利用这一点。
如果您希望您的实体在 CUBA 中支持多租户,则需要实现一个特殊的接口 - com.haulmont.cuba.core.entity.TenantEntity。 这时,扩展将会考虑用于租户数据隔离的特殊列。举个例子,下面是 Pet 实体的代码片段:
public class Pet extends NamedEntity implements TenantEntity {
@TenantId
@Column(name = "TENANT_ID")
protected String tenantId;
@NotNull
@Column(name = "IDENTIFICATION_NUMBER", nullable = false)
protected String identificationNumber;
@OneToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "TYPE_ID")
protected PetType petType;
请注意,CUBA 中所有“系统级”实体都默认支持多租户。因此,您可以为每个客户隔离用户、角色、保存的过滤器、安全组等。
创建实体后,CUBA 将为多租户实体生成的所有 JPQL 查询(包括联接)添加一个额外条件 “where tenant_id=
例如,如果我们要从宠物诊所数据库中选择宠物和主人,则最终查询语句将如下所示:
SELECT *
FROM PETCLINIC_PET t1
LEFT OUTER JOIN PETCLINIC_OWNER t0
ON ((t0.ID = t1.OWNER_ID)
AND (t0.TENANT_ID = t1.TENANT_ID))
LEFT OUTER JOIN PETCLINIC_PET_TYPE t2
ON (t2.ID = t1.TYPE_ID)
WHERE ((t1.TENANT_ID = 'clinic_one') AND (t1.DELETE_TS IS NULL))
请注意查询中的条件:AND (t0.TENANT_ID = t1.TENANT_ID)) 和 (t1.TENANT_ID = 'clinic_one') 。 这是 CUBA 扩展自动添加的。
但是,除了应用程序级别,是否有办法在数据库级别透明地应用多租户? 答案之一是 Citus 。
Citus: PostgreSQL 中的多租户
正如 这篇文章 所述: “Citus 是提升 Postgres 可伸缩性的的完美方案。 这是 Postgres 的扩展,可以在多台计算机的群集中分发数据和查询。作为扩展(而不是分支),Citus 支持新的 PostgreSQL 版本,使用户可以从新功能中受益,同时保持与现有 PostgreSQL 工具的兼容性。Citus 使用分片和复制功能在多台计算机上水平扩展 PostgreSQL。它的查询引擎可以在这些服务器之间并行处理传入的 SQL 查询,从而可以对大型数据集进行实时(不到一秒钟)响应。”
看来 Citus 解决了有关创建多租户应用程序的许多问题。它允许我们使用 “为每个租户使用单独数据库” 的方法来存储每个租户数据,但从应用程序开发的角度来看,还像是面向单个数据库。所有查询均根据 Citus 群集创建期间定义的规则进行修改。
这意味着您可以使用 CUBA 多租户实现和物理隔离的数据库来构建多租户应用,而无需重写查询。让我们深入看看 Citus 数据库的创建过程。
首先,您需要创建一个数据库集群并向其中添加节点。集群由协调节点和工作节点组成。每个工作节点都存储特定租户的数据,并且协调器将根据 “tenant_id” 列重新路由查询。应用程序仅将查询发送到协调器。这个过程如下图所示(摘自 Citus DB 文档):
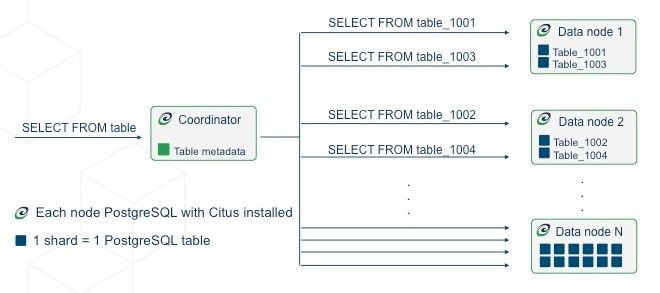
另外,要使用 Citus,您需要在数据库创建期间定义表类型。 有三种类型:
- 分布式表 - 这些表分布在工作节点。它们包含特定于租户的数据。
- 参考表 - 存储所有租户均可使用的信息的表。对于 PetClinic 示例, “Specialty” 和“PetType” 表可共享。
- 本地表 - 在分布式表或参考表的联接查询中未使用的服务表。例如存储在协调器节点上的 Cituses 本身的元数据表。
企业版 Citus 可通过使用以下操作来显式地隔离租户数据:
SELECT isolate_tenant_to_new_shard('table_name', 'tenant_id');
这将替换默认的的基于哈希算法的分区。
在 CUBA 中使用 Citus
对于 CUBA 应用程序,我们不需要重写应用程序的代码,但是需要修改数据库和表的创建过程以便 “与 Citus 兼容”。我们都喜欢 CUBA 的 SQL 生成魔术,但是不幸的是,您必须手动创建一些脚本以支持 Citus。
数据库创建过程发生变化。您需要创建 Citus 扩展,添加节点并启用复制:
CREATE EXTENSION citus;
SELECT * from master_add_node('localhost', 9701);
SELECT * from master_add_node('localhost', 9702);
SET citus.replication_model = 'streaming';
好处是,您可以大部分时间在本地 “普通” 的 PostgreSQL 上开发应用程序,仅在部署到演练或生产环境(如果您胆大心细也许就不需要演练了)之前添加特定于 Citus 的表创建脚本。唯一更改的是数据库地址 - 您需要指定 Citus 集群协调器数据库地址,而不是本地开发数据库。
对于数据库的创建和更新,您需要像下面这样显式指定分布式表(表名称和分区列):
SELECT create_distributed_table('petclinic_vet', 'tenant_id');
SELECT create_distributed_table('petclinic_owner', 'tenant_id');
SELECT create_distributed_table('petclinic_pet', 'tenant_id');
SELECT create_distributed_table('petclinic_visit', 'tenant_id');```
对参考表做类似的处理:
SELECT create_reference_table('petclinic_specialty');
SELECT create_reference_table('petclinic_vet_specialty_link');
SELECT create_reference_table('petclinic_pet_type');```
为了提高性能,除了分区之外可以添加表 协同定位(co-location) 。但是在 CUBA 中您不需要做任何修改,多租户是一个绝对透明的过程。
就这样,用最少的努力,我们就可以实现水平扩展 PetClinic 应用程序,也可以在数据库级别使用多租户。所有的复杂性都隐藏在 CUBA 框架和 Citus 插件中。
总结
创建多租户应用程序可能是一项艰巨的任务。在开始实施这种方法之前,应考虑所有选项,技术只是方程式的一部分:您需要考虑许可成本、云服务资费、可维护性、可扩展性等。如今,PaaS 模型以及容器化和正确的 DevOps 流程比 “传统” 多租户架构更具吸引力,但对此类应用程序的需求仍然很明显。
如果您决定继续使用多租户架构,请确保您的应用程序符合所有安全要求,例如 GDPR、HIPAA 等。其中某些可能明确禁止在同一数据库中存储数据,因此您需要使用 “独立数据库” 方法来满足这些要求。