





根本原因
开发人员通常不喜欢改变他们编码的习惯。当我刚开始接触 CUBA, 的时候,发现不需要学很多新的东西,创建应用程序的过程也是非常顺利的。但是其中有一样是需要重新学习的,那就是如何使用数据。
在Spring框架中,有好几个库可以用来处理数据,其中最流行的一个就是 spring-data-jpa,使用这个库可以使开发人员在很多情况下避免编写SQL或者JPQL。只需要创建一个接口类,然后在接口中创建 带有特殊名称 的方法,Spring会自动帮你创建和执行查询语句。
比如,这里有一个接口,其中有个方法是数数有多少客户是同一个姓的:
interface CustomerRepository extends CrudRepository<Customer, Long> {
long countByLastName(String lastName);
}
可以直接将这个接口注入到service中,然后就可以在需要的地方调用这个方法了(注意,不需要写实现类)。
CUBA提供了很多开箱即用的数据操控方法,比如加载实体的部分属性以及成熟的数据安全子系统 - 可以限制数据访问权限至实体属性和表数据的行级别。并且这些所有的功能都带有API,但是跟大家都知道的Spring Data或者JPA/Hibernate的略有不同。
所以,为什么在CUBA中没有上面说的查询接口?有没有可能添加呢?
CUBA中使用数据的方式
CUBA的API中有三个主要的类用来处理数据:DataStore,EntityManager 和 DataManager。
DataStore 的抽象是提供处理持久化存储的API,比如RDBMS,文件系统或者云存储。可以通过DataStore执行基本的数据操作,但是,不推荐直接使用DataStore,除非需要开发自定义的持久化存储或者需要对底层存储进行非常特殊的访问。
EntityManager 很大程度上只是JPA EntityManager 的拷贝,但是有额外的方法用来处理 CUBA视图、软删除以及 CUBA 查询语句。作为CUBA开发人员,很少在日常工作中使用这个类,除非需要克服CUBA的安全限制。
下一个要说的,DataManager,是在CUBA中处理数据主要使用的类。此类提供了处理数据的API并且支持到属性和行级别的 CUBA安全模型 。当查询数据的时候,DataManager会隐式的修改查询语句。比如,在关系型数据库中,它会更改“select”语句,排除那些受限的属性,然后自动添加“where”语句来筛选那些当前用户不能看到的数据行。这种安全感知的行为是很有帮助的,开发人员不需要死记在查询语句中需要添加哪些关于安全方面的条件。
这里有个CUBA类交互的图,展示使用DataManager从RDBMS中获取数据的过程。
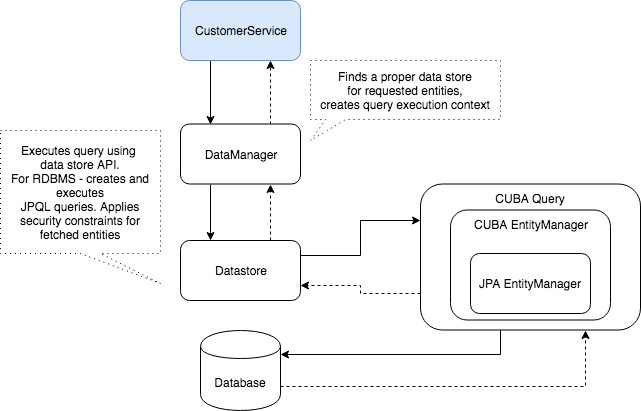
使用DataManager可以相对容易的查询实体(或者使用CUBA视图查询实体层级结构)。最简单的查询是这样:
DataManager会自己过滤掉“软删除”的记录、受限制访问的实体属性或实体,也会自己创建数据库事务。
dataManager.load(Customer.class).list()
但是如果需要执行带有复杂“where”条件的查询语句,就需要写JPQL了。
看看最开头那个例子,如果需要按姓统计客户人数,在CUBA中需要写这样的:
public Long countByLastName(String lastName){
return dataManager
.loadValue("select count(c) from sample$Customer c where c.lastName = :lastName", Long.class)
.parameter("lastName", lastName)
.one();
}
public Long countByLastName(String lastName){
LoadContext<Person> loadContext = LoadContext.create(Person.class);
loadContext
.setQueryString("select c from sample$Customer c where c.lastName = :lastName")
.setParameter("lastName", lastName);
return dataManager.getCount(loadContext);
}
这里可以看到,需要将JPQL语句丢给DataManager去执行。在CUBA API里,JPQL需要用字符串来定义(目前还不支持Criteria API)。JPQL有很好的可读性,也能清晰的定义一个查询语句,但是如果出问题,可能不是很好调试。另外,JPQL字符串不像Criteria API那样能在构建编译时进行验证,或者在Spring上下文初始化的时候验证。
比较一下Spring Data JPA 的接口:
interface CustomerRepository extends CrudRepository<Customer, Long> {
long countByLastName(String lastName);
}
这个接口只有三分之一的代码量而且不包含任何显式的字符串。此外,countByLastName 方法会在部署阶段验证。如果方法名敲错了,比如,敲成 countByLastNome,则会有异常抛出:
Caused by: org.springframework.data.mapping.PropertyReferenceException: No property LastNome found for type Customer!
由于CUBA也是基于Spirng框架构建的,所以可以将Spring-data-jpa添加为CUBA项目的依赖库然后使用这个功能。唯一的问题,Spring的查询接口底层使用JPA的EntityManager,所以查询语句不会被CUBA的EntityManager或者DataManager处理。因此,需要找到合适的方法在CUBA中添加查询接口 - 需要自定义,所有调用EntityManager的地方都需要用CUBA的DataManager相应的方法替换,并且添加对CUBA视图的支持。
也有人会说,使用Spring的方案不如CUBA的方案可控,因为不能控制生成查询语句的过程。这是在便利性和抽象化级别之间的平衡问题,需要开发者决定到底使用那个方案。但是有个额外的处理数据的简单方法总是没坏处,尽管这也不是唯一的方法。
如果需要更多的控制,Spring里也有方法为接口指定查询语句,所以这个方法也需要添加到CUBA。
实施
查询接口使用 spring-data-commons 实现,构建为CUBA应用程序组件。这个库包含实现自定义查询接口的类,比如,Spring的spring-data-mongodb 库就是基于这个实现的。Spring-data-commons利用代理技术来为声明式查询接口创建正确的实现。
在CUBA的上下文初始化期间,查询接口的引用都会被生成的代理bean隐式替换。当开发人员调用接口方法时,相应的代理会进行拦截。然后代理根据方法名称生成JPQL查询,替换参数值,并交给DataManager执行。下图展示了模块关键组件之间的简单交互过程。
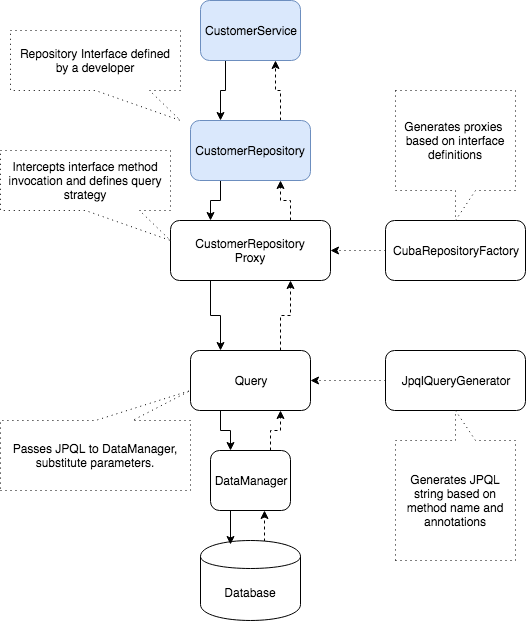
在CUBA中使用查询接口
需要在项目的构建文件中添加新的应用程序组件才能使用CUBA的查询接口:
appComponent("com.haulmont.addons.cuba.jpa.repositories:cuba-jpa-repositories-global:0.1-SNAPSHOT")
XML configuration to enable query interfaces:
<?xml version="1.0" encoding="UTF-8"?>
<beans:beans xmlns:beans="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:repositories="http://www.cuba-platform.org/schema/data/jpa"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-4.3.xsd
http://www.cuba-platform.org/schema/data/jpa
http://www.cuba-platform.org/schema/data/jpa/cuba-repositories.xsd">
<!-- Annotation-based beans -->
<context:component-scan base-package="com.company.sample"/>
<repositories:repositories base-package="com.company.sample.core.repositories"/>
</beans:beans>
如果习惯使用注解而不是创建XML配置文件,可以用下面的方法启用查询接口:
@Configuration
@EnableCubaRepositories
public class AppConfig {
//Configuration here
}
启用查询接口后,可以在应用程序中创建并使用。下面是示例:
public interface CustomerRepository extends CubaJpaRepository<Customer, UUID> {
long countByLastName(String lastName);
List<Customer> findByNameIsIn(List<String> names);
@CubaView("_minimal")
@JpqlQuery("select c from sample$Customer c where c.name like concat(:name, '%')")
List<Customer> findByNameStartingWith(String name);
}
可以在接口方法上使用 @CubaView 和 @JpqlQuery 注解。第一个注解定义需要使用的视图(如果没有使用这个注解默认使用“_local”视图)。第二个注解是用来设置JPQL的,用在查询语句不能通过方法名表示的时候。
查询接口的应用程序组件是绑定到CUBA的“global”模块,所以可以在“core”和“web”模块定义和使用查询接口,只是别忘了在相应的配置文件中启用接口。接口使用的示例:
@Service(CustomerService.NAME)
public class CustomerServiceBean implements PersonService {
@Inject
private CustomerRepository customerRepository;
@Override
public List<Date> getCustomersBirthDatesByLastName(String name) {
return customerRepository.findByNameStartingWith(name)
.stream().map(Customer::getBirthDate).collect(Collectors.toList());
}
}
结论
CUBA很灵活。如果觉得需要为应用程序添加新的功能,又不想等CUBA的新版本,很容易在不修改CUBA核心的情况下实施并添加到项目中。通过为CUBA添加查询接口,我们希望能帮助开发人员更加有效的工作,更快的交付可靠的代码。这个库的第一个版本可以在GitHub找到,目前支持CUBA 6.10和更高版本。